Day 3 Notes
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
The process of learning itself is not the task. (Learning is our means of attaining the ability to perform the task.)
types of experience
- supervised (data is labelled, or a target is specified),
- unsupervised (features are learned from unlabelled data)
- reinforced (no data is given, learning happens via interaction with an environment),
types of tasks (not complete):
- classification (supervised)
- sort input into a predetermined set of categories
- e.g. object recognition, face recognition
- image classification demo: https://www.clarifai.com/demo
- clustering (unsupervised)
- sort input into arbitrary categories
- regression
- predict an output given some input
- e.g. predicting prices, drawing a new image based on an original
- transcription
- unstructured data —> structured sequence
- e.g. optical character recognition (image to text), speech recognition (audio to text)
- translation
- structured sequence —> structured sequence
- structured output
- outputs multiple values that are related to each other in some way
- e.g. parsing a sentence into parts of speech, providing a caption for an image
- anomaly detection
- picks out unusual examples from an input set
- e.g. fraud detection
- synthesis
- similar to “structured output”, but variation in output is valued:
- generating texture
- synthesizing speech
- similar to “structured output”, but variation in output is valued:
- suggesting or generating missing items of a set (unsupervised)
- interpellation
- compression
- denoising
- predicting a “clean” example from a “corrupted” example
performance measure
(how training happens)
also referred to as the cost function.
- back propagation: weights are adjusted moving from output layer back towards input layer
- gradient descent: a performance measure for the performance measure, or, which direction does each change in weight push the overall network?
- beware of overfitting - the challenge of fitting the training data differs from the challenge of finding patterns that generalize to new data
a few types of artificial neural networks
“feedforward networks”
perceptron
multilayer perceptron
Each connection between neurons carries a trainable Weight and offset Bias. By adjusting these values through a training process, the strength of individual connections are made stronger or weaker.
In a single layer type, Input Neurons are connected directly to Output Neurons.
In a multilayer type, Hidden Layer Neurons each have their own activation function.
“Recurrent Neural Networks” (RNN)
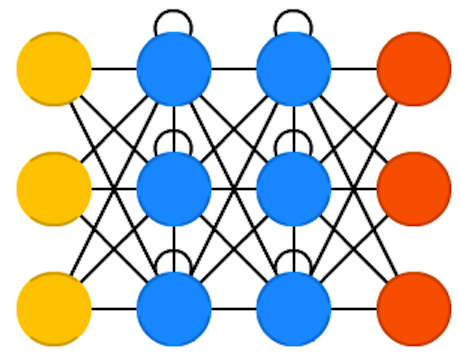
RNN (Recurrent Neural Network)
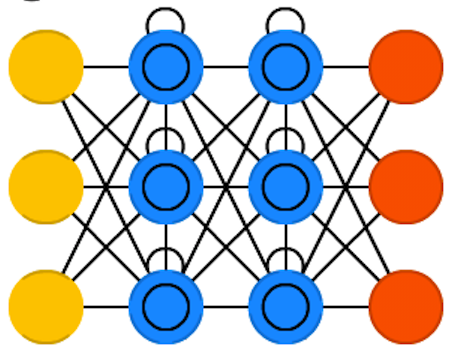
LSTM (Long / Short Term Memory)
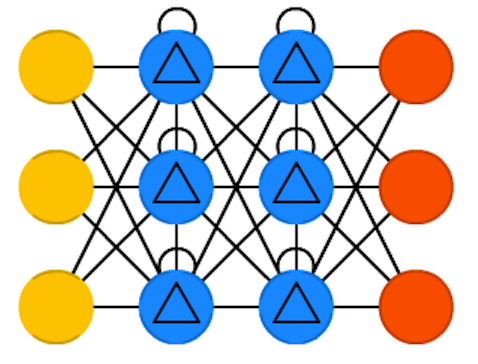
GRU (Gated Recurrent Units)
used when sequence is important (what came before determines what comes next)
can be generalized to include text, audio, video (anything time-based), attention (scanning a scene, etc.)


Further Reading:
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Demos:
- https://aiexperiments.withgoogle.com/ai-duet/view/